Airflow
Article covers Airflow architecture for beginner enterprise ml team
Through year I had intensive work with Airflow as MLOps specialist. My primer task was to facilitate in-house Airflow provision. I’ll share ideas and setup, that
Blog divided in three parts:
- Linkage between tools of versioning Gitlab, storage s3 and Airflow
- Covers responsibility delegation in team
- Suggest code for introduced concepts
If you prefer, you can material on youtube or look through presentation
Why care?
Following chapter is pure introduction and inspiration. You can skip it freely, if you want :)
Pipelines
Pipelining is an art of organization domain specific tools. They skill helps to fasten things a lot, since there are a lot of cool open source tools.
 |
|---|
| Pipelining is an art of organization |
Such pipes are handled by ‘glue’ shell scripting languages like bash
mkdir -p traced_images && cat img_path.txt | xargs -I {} potrace {} -O
Parallel with old tools like bash is essential as documentation of orchestration assumes that you have profficience with and recognized it’s limit. Mainly because such tools doesn’t go well beyond one machine and sysadmin. Therefore we need better tools
 |
|---|
| Something more scalable |
Orchestration
Orchestration is a way of renormalizing pipelining on level of systems. It contains lot’s of pipelines and soon after srchestration tool are basically become project heart.
 |
|---|
| Comes |
Therefore orchestrators come with tools of adaption to environment modification and wiring.
 |
|---|
| Renormalization |
Tools
Section will provide setup explanation and
Before we start I’ll share some core concepts about Airflow.
Airflow. Brief introduction
Apache Airflow is an open-source platform designed to programmatically compose pipeline, schedule them and monitor them in powerful UI. Main language is Python
Basic primitive is a Directed Acyclic Graphs (DAGs).
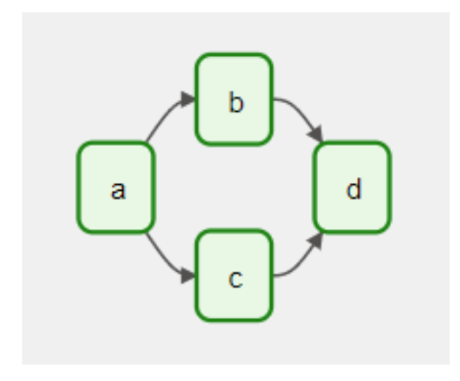 |
|---|
| Intuitive representation of pipeline |
Nodes here represents action to executed, links it’s order.
That abstraction is boosted with scheduling
For better perception can be organized in groups.
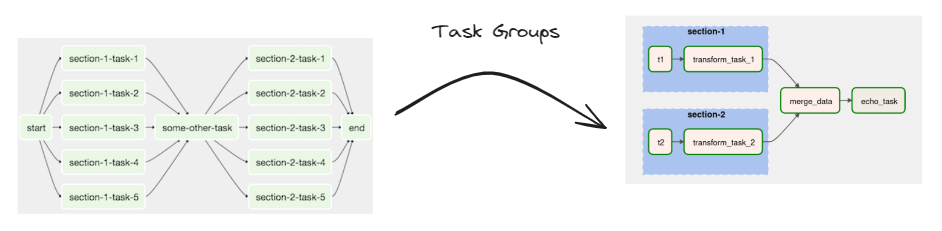 |
|---|
| Semantic organization |
By default operators are executed via Celery, but can also be modified for running on Kubernetes.
You can learn more about Airflow from official documentation on DAG. If you want to practice, you can also refer to my tutorial on starting with Airflow on toy OCR app Github Link.
I’ll warn you that from outbox Airflow:
- doesn’t provide any options for .
Setup
In-house solution already done all all DevOps work of the deployment, configuration, and monitoring of Airflow instances. Provider ensured scalability, reliability, and performance.
Pipelines are provided to Airflow via cli command, which can be executed both locally and
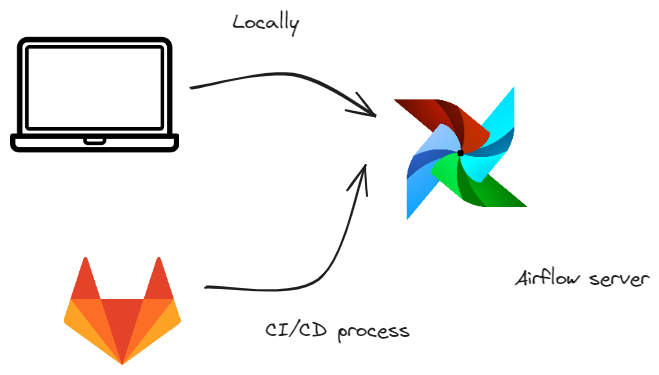 |
|---|
| Our dream team |
Yet it comes with restriction of Airflow environments, manage dependencies, which could be mitigated with building custom airflow docker image.
Moreover, it introduced convenient way of job execution defined by yaml. It’s api is quite transparent, I’ll provide you comments to
job:
resourse_flavor: cpu-16gb # configures amount of cpu, gpu and ram
docker_image: python3-11 # sets image
excecution_time: 60 minutes # time of execution. After job ungracefully shuts
execution_script: python main.py # defines script that will be executed through job
And a way of handling big files from executions through s3
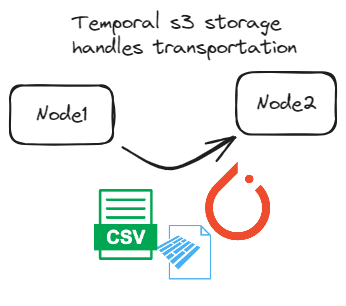 |
|---|
| Transportation as a service |
Therefore introduced techniques are primarly oriented for effective utilizations of provided features and effective ML team collaboration.
Problems 🚨
Main problem were:
- testing models inference and node functionality was extremely on server
- monitoring of dags execution and data delivery
- environment setting
- no reasonable solution for reuse of already prepared dag
I’ll introduce solution for every problem through next paragraphs
CLI apps for testing
Cli apps facilitate testing as their should behave equally in fast local environment and
When app is ready we can have following options
- push to Python package storage, from where we’ll pip install it in execution job
- make a docker image with install cli option
 |
|---|
| Our dream team |
Model delivery
Also repo contains reproduction code for model. Reproduction is done with usage
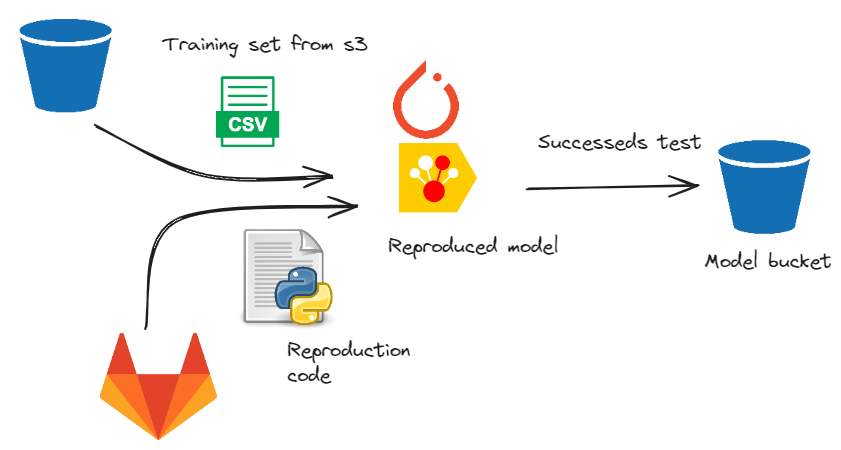 |
|---|
| Training is performed in job, that is called in CI script. Than model proceeds to designated model bucket |
Every option is actually great and should be facilitated for usage
Pipeline for repetitive code
Main observation was that dags are mostly similar and has structure of Extract Transform Load(ETL).
Therefore they can be replaced with simple yaml structure. I’ll provide you with prototype
dag: # dag info
name:
schedule: " " # simple cron expression
base_resourse: cpu
critical: true
tasks:
read: # arbitrary group name
load_csv: # arbitrary task name
operator_type: pg_to_csv
columns:
- ham
- bam
...
Such solutions allows to abstract from Airflow and can be scaled via interactive UI. Moreover, it is useful for versioning of code and correction on fly from gitlab editor.
Overall pipeline looks like:
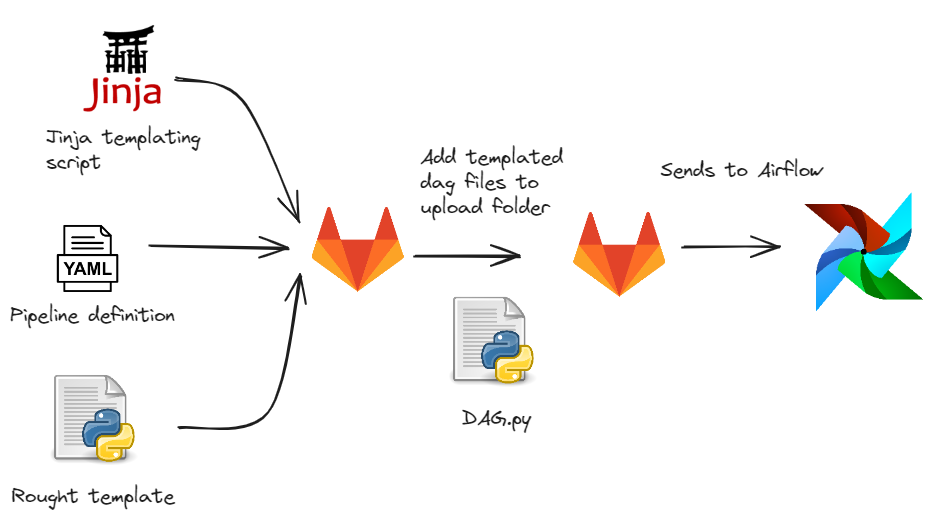 |
|---|
| Gitlab templates blank for each yaml pipeline definition |
There are some open-source, that already implemented yaml declarative approach:
- dag-factory: https://github.com/ajbosco/dag-factory
- airflow-declarative: https://github.com/rambler-digital-solutions/airflow-declarative
Environment variables
Unfortunatelly we don’t have access to environment variables of Airflow. Therefore we have two options:
- set environments from UI, which is not scalable
- set environment of Airflow can be defined through Airflow variables
Second option is better, yet it requires quite long chain for completion.
|
|---|
| Training is performed in job, that is called in CI script. Than model proceeds to designated bucket |
Basically configuration yaml look like that:
postgres_db_connection:
password: ${PG_PASSWORD}
Bash util envsubst will fill fields as ${PG_PASSWORD} with respect value from Gitlab CI variables.
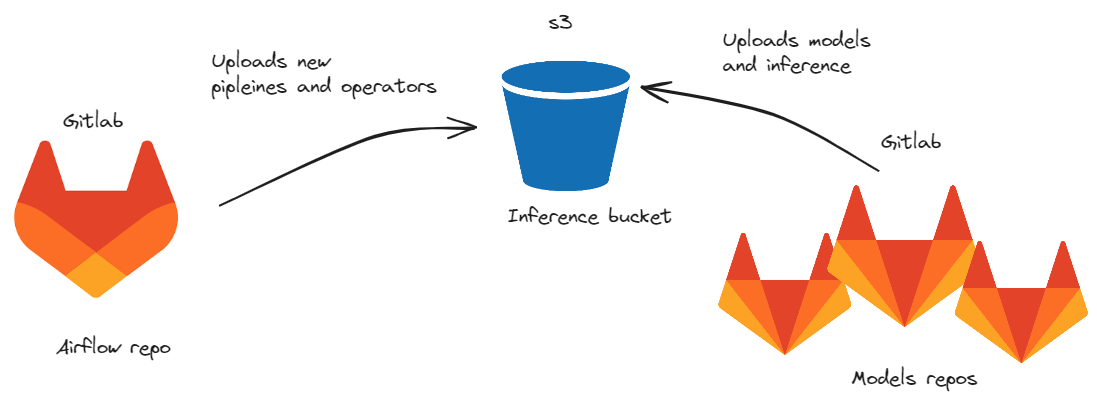
Before we can start inference we need to deliver our files to production. Our provides can grab files for inference from s3.
Repository of airflow and model were separated
Team
Architecture is seeking for ability for delegating responsibilities
Responsibility delegating
Business critical processes requires swift responses for change of production environments . Hence specialists should be able to effectively collaborate in critical situations.
Commonly used technique for that is introducing role model for specialists with.
Airflow team
Management
 |
|---|
| Our dream team |
Note that every specialist should be essential, beneficial for and has an ability to master his skills.
Data Scientist
Analytic concentrates on novel ideas for models and bring/
 |
|---|
| Provider of novel ideas |
Growth:
 |
|---|
| Stronger algorithm generalization |
Main track of learning is providing more flexible solutions. It includes:
- search new ideas, incorporating new solutions
- creating valence operators, that can handle arbitrary amount and type of data
- provide best solution for analytic task
- data quality organization
Data engineer
He knows bases of devops, yet specify his skills in building robust and flexible pipelines. Although role can be modified via
 |
|---|
| Builds functional operator, scales code |
Engineer is mostly responsible for:
- help of analytics with optimal pipeline solution
- development of new operator for connection
- bringing
Main track of learning is providing more flexible solutions. It includes:
- gluing code with bash
- creating valent operators, that can handle arbitary amount and type of data
- provide best solution for analytic task
- data quality organization
 |
|---|
| Builds functional operator, scales code |
Although he helps to relaxate climax situation. He helps analytic and discuss tests.
Developer
Mostly responsible for:
- scalability
- introducing CI building process
- ease of configuration Therefore role ease building of new dags and their monitoring.
 |
|---|
| Scales and rescales |
 |
|---|
| Developer learns scaling |
CLI as communication protocol
Support for pipeline in working condition is mainly responsibility of engineer therefore he need to make sure, that Data Scientist code is reliable.
Cli app coupled with tests is simple, yet effective way to do that:
Team interaction
Should be formalized and adversarial for growth. Interaction between engineer and analytic
 |
|---|
| Interaction should be objective and implicit |
Will discuss
Big csv
Suppose pur pipeline succeeds in business application and comes time for scaling. Hence input starts to come in greater amount, which can not be handled with same resources.
 |
|---|
| Scaling can be painful for DS |
Yet pandas dataframe isn’t best format for handling big data, as it’s not provide memory efficient storage. That can be optimized via challenging more and more tools like Polars, Ray and Spark. Yet business can not always wait for this
 |
|---|
| Scaling can be painful for Data Scientist |
Therefore, simple bash solution can handle problem more implicitly
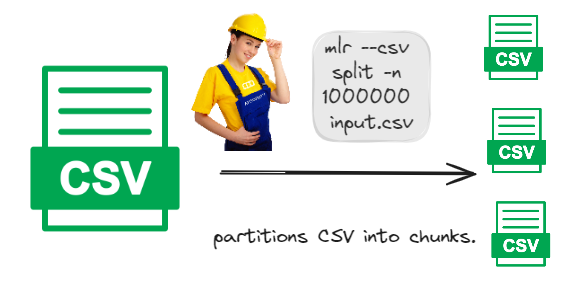 |
|---|
| Branch and bound |
Engineer can solve problem in one line of code, which can ease first steps and proceeds with studying of goal framework. Re
So that they can be gracefully proceeds with analytic codes.
Critical job falls and analytic want to revert to previous version
Developer should
Code implementation
Nitty details of implementation
s3 environment organization
Setting Airflow variables
Environments helps to test new ideas
from airflow.models import Variable
Variable.set(key="db_url", value="")
Variable.set(key="my_json_var", value={"num1": 23, "num2": 42}, serialize_json=True)
Airflow operators are projected such way, that they change their behaviour with respect to current Airflow variables
from airflow.models import Variable
Template from yaml structure
Recall structure of pipeline yaml file
group: # arbitrary group name
task: # arbitrary task name
operator_type: pg_to_csv
columns:
- ham
- bam
Resulted py file for airflow execution is done with jinja. You can read my code in following github
Note that there is an alternative approach through globals() as it was done in airflow-declarative. Yet it less explicit as it doesn’t produce resulted python files.
Node based programming
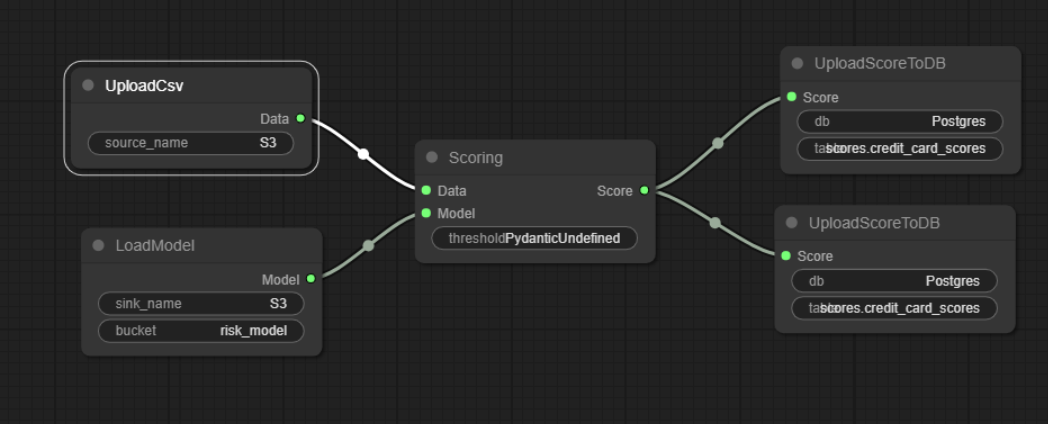 |
|---|
| Open source solution for class connection |
For ease of building new dags I introduced solution based on LiteGraph.
Solution was highly inspired by ComfyUI pipelining tool for Stable Diffusion.
Summary
Thank for your reading. Hope that provide some intuition for your team. I compiled article insights for you
- Role model is convenient way of organizing team. Primarily, there are three basic roles: Data Scientist - business insights seekers, Engineer - support and critique, Developer - wires, monitors and rescales
- Yaml is convenient both for defining pipelines and configs
- decoupling of model and airflow repo can be done via s3
- partite s3 for models. That allows flexible versioning of data and models.
- cli is nice interface for interaction between engineer and data scientists