Neuroscience
Brief overview of advances in conjunction of Deep Learning and neuroscience
Biological networks are much more than just scalar weights. It has activation time and phase different phases of work. Recent works have proved efficacy of neuro-informed approaches.
Difference between biological and artifical neural nets
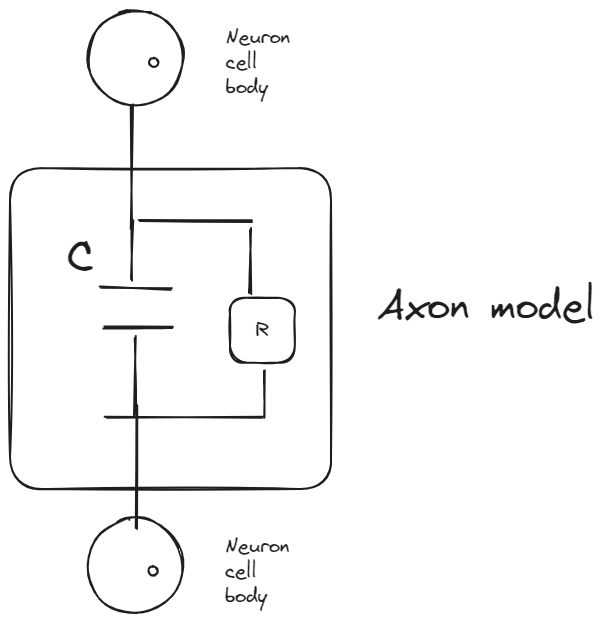
Neurons are interconnected with axons, which transmits signals between neurons. Signals are formed as spikes
 |
|---|
| Axon connects neuron cell bodies |
Spiking models
Integrate-and-fire model coresponce to electrial view of axon
|
|---|
| Axon connects neuron cell bodies |
Capacity of synaptic is remained unseen. Yet it’s
Latent representation
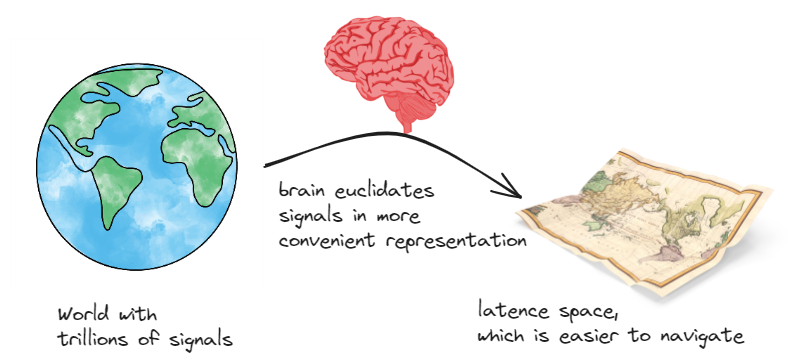
Represents world events in his own latent space. In easiest case it is just a representation of place
 |
|---|
| ** |
You can learn more about manifold in blog.
Hypothesis of latent representation is well studied and summarized via biological perspective in excellent videos of Artem Kirsanov Neural manifolds - The Geometry of Behaviour and Your brain is moving along the surface of the torus 🤯.
Latent representation are unique among all people. Yet we are capable to share via communication, which have certain formats. Through perspective of machine learning that is called Sparse coding. That idea is very similar to basis in linear algebra.
 |
|---|
| Communication has lot’s of forms |
From experience of communication we learn to correspond specific communication as certain combination of semantic recognition.
One more insight. Motion integrals
When you sit in a train, you don’t check to , you just remember it.
|
|---|
| Communication has lot’s of forms |
From perspective of analytic mechanics it means that we coresponds to first integral. That means in your semantic space you can decouple preserving and changing.
Moreover, we can say that through years we learn to do that with many things. We learn them an. That helps to concentrate on real
How brain learns?
Backpropogation is highly successful algorithm for learning ANN (artificial neural nets), yet it doesn’t have proper analogy with biological systems.
Work Backpropagation and the brain Basically there are few hu
- Hebian learning. It forms the basis for unsupervised learning algorithms such as Hebbian networks and self-organizing maps (SOMs). These algorithms use the principle of strengthening connections between neurons that are frequently activated together, allowing the network to form representations of input patterns in an unsupervised manner.
- Perurbation
Effectiveness of backpropogation is connected with fact that instead of seeing result of perturbing of singular weight to see change of output it’s possible. It comes necessity of integration and redirect attention towards stationary neural nets, which is not biologically plausible. Refer to The recent excitement about neural networks to learn more about.
Hopfield networks
Are tightly correspondent to Ising models of spin glasses
\[E = \frac{1}{2} \sum_{i,j=1}^n w_{ij} v_i v_j + \theta\]$v_i$ corresponds to spin orientation and hold values between
Hopfield networks are learned throught update rules which may me:
- In synchronous updating, all neurons in the network update their states simultaneously at each time step.
- In asynchronous updating, only one neuron is updated at a time, chosen randomly or sequentially. The new state of the chosen neuron is calculated based on the current states of other neurons in the network.
Continious in time
\[\frac{d}{dt} u_i = \frac{-u_i}{\tau} + \sum_{j=1}^n w_{ij} + \theta_i\]Spherical spin glass
Description mostly from paper by Yann LeCun The Loss Surfaces of Multilayer Networks https://arxiv.org/pdf/1412.0233.pdf. Work considers feed-forward deep network with single output for modeling.
Spherical constrain
\[\frac{1}{\Lambda} \sum_{i=1}^\Lambda w_i^2 = \mathrm{C}\]Ensembles
Combinatorial representation of system as possible collections of states
Why we need lot’s neuronms
Symmetry can exhibit various dimensions. Describing a rotation transformation in n-dimensional space requires a minimum of n-1 parameters. If represented as a matrix, the parameter space expands by a factor of n. Within a grid, this transformation is learned as a distinctive structure, which may further augment its complexity.
 |
|---|
| Example of high dimensional symmetry that embedded in 2 dimensional picture |
Look at following picture. One of the symmetry that net might learn is that all cars, therefore they can be permuted without loss of sense.
\[P = \begin{pmatrix} 0 & 0 & \cdots & 1 & \cdots & 0 \\ 0 & 0 & \cdots & 0 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots \\ 1 & 0 & \cdots & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots \\ 0 & 1 & \cdots & 0 & \cdots & 0 \end{pmatrix}\]For learning such symmetries we high dimensional matrix, hence more neurons
Neural coding
A way how brain transfer information.
Liquid networks
Is’s a conspect from Liquid Neural Networks
Leaky-integrator model
\[\frac{d \mathbf{x}}{d t} = - \frac{\mathbf{x}(t)}{\tau} + \mathbf{S}(t)\]Conductance-based synapce model
\[\mathbf{S}(t) = f(\mathbf{x}(t),\mathbf{I}(t),t, \theta)(A - \mathbf{x}(t))\] \[\frac{d \mathbf{x}}{d t } = - \left[ \frac{1}{\tau} + \underbrace{f(\mathbf{x}(t,\mathbf{I}(t),t,\theta)}_{\text{Liquid variable}}) \right] \mathbf{x}(t) + f(\mathbf{x}(t,\mathbf{I}(t),t,\theta)) A\] |
|---|
| Screenshot from presentation |
New Hopfiled networks
Recall that are two type of states
Were introduced in Paper Dense Associative Memory for Pattern Recognition https://arxiv.org/abs/1606.01164
Old pair-wise interaction
\[E = - \frac{1}{2} \sum_{i,j=1}^N \sigma_i T_{ij} \sigma_j\]New non-linear
\[E = - \sum_{\mu =1}^K F(\xi_i^\mu \sigma_i)\]Which comes in exponential increase in capacity of stored memories.
With drawback of that we need to store all of them
Increased capacity of recognised
Reservoir computing
Next generation reservoir computing https://www.nature.com/articles/s41467-021-25801-2
Introduction to Next Generation Reservoir Computing https://www.youtube.com/watch?v=wbH4En-k5Gs
Forward-forward
Backpropagation and the brain https://www.nature.com/articles/s41583-020-0277-3
Checkout notebook
https://github.com/EscVM/EscVM_YT/blob/master/Notebooks/2%20-%20PT1.X%20DeepAI-Quickie/pt_1_forward_forward_alg.ipynb
Read more
-
Neuronal Dynamics and corresponding Neuronal Dynamics: Python Exercises
-
Fokker-Plank equation https://www.youtube.com/watch?v=vPrDNKEJRM8&list=PL7SYVykTNxXa7D2DyqA33CNRir8Hp-Uvd&index=4
-
LeCun Latent World . Here is effective paraphrase of article. For effective work we need to concentrate, despite changing. For that we have instrisic representation of world. It helps to find something that preserves in time, so we need ti
-
HAMUX https://github.com/bhoov/hamux
-
Free energy Karl Friston https://www.fil.ion.ucl.ac.uk/~karl/A%20free%20energy%20principle%20for%20the%20brain.pdf
-
Relating transformers to models and neural representations of the hippocampal formation https://arxiv.org/abs/2112.04035